Special Issue 5 - OuNuPo
XPUB, Varia and WORM invite you for an evening of book scanning, short presentations, discussions and software experiments in the context of text digitisation and processing. 28/03/18 - 19:00 at WORM
OuNuPo, Ouvroir de Numérisation Potentielle, the workshop of potential digitisation

From January until the end of March 2018 the practitioners of the Media Design Experimental Publishing Master course (XPUB) of the Piet Zwart Institute, in collaboration with Manetta Berends & Cristina Cochior (Varia) and the WORM Pirate Bay, have set sail on the vast sea of DIY book scanning, feminist research methodologies, constraint writing, algorithmic literature and the cultures of text digitisation and processing.
The term OuNuPo is derived from OuLiPo (Ouvroir de littérature potentielle), founded in 1960. OuLiPo is a mostly French speaking gathering of writers and mathematicians interested in constrained writing techniques. A famous technique is for instance the lipogram that generates texts in which one or more letters have been excluded. OuLiPo eventually led to OuXPo to expand these creative constraints to other practices (OuCiPo for film making, OuPeinPo for painting, etc). Following this expansion, XPUB launches OuNuPo, Ouvroir de Numérisation Potentielle, the workshop of potential digitisation, turning the book scanner as a platform for media design and publishing experiments.
In the past three months, the XPUB practitioners have used OuNuPo as a means to reflect on several topics: how culture is shaped by book scanning? Who has access and who is excluded from digital culture? How free software and open source hardware have bootstrapped a new culture of librarians? What happens to text when it becomes data that can be transformed, manipulated and analysed ad nauseam?
To answer these questions, the XPUB practitioners have written software and assembled a unique printed reader, informed by critical and feminist research methodologies. The text selection explores the themes of the digital transfer of cultural biases, Techno/Cyber/Xeno-Feminism, oral culture in the context of knowledge sharing, shadow libraries, database narratives, gender and future librarians. The content of the reader will be scanned by a DIY book scanner built in the past months, and processed by different software processes and performances written by the XPUB practitioners, from chat bots to concrete poetry generators and speech recognition feedback loops.
Inside the workshop of potential digitisation:
To approach the workshop of potential digitisation, the following strategy was adopted: two book scanners were built using a variation of the Archivist Book Scanner, a 2014 public domain (CC0 licensed) hardware design developed within the DIY Book Scanner community. Next to that, a unique reader was put together in the form of 6 books on scanning cultures, edited, designed and produced by the XPUB practitioners. Each book is a compilation of 5 to 10 annotated texts addressing a specific question, or topic, relevant to the practitioners. The 6 books are gathered inside a cloth, folded according to the Japanese Furoshiki art of wrapping. Finally, instead of using the book scanner as a mere text scanning and PDF creating apparatus, each XPUB practitioners wrote their own text processing software to echo, reflect upon, or explore further their reading material as a means to articulate through code the two levels of textual interpretation and dissemination: the human and the machine. Using the book scanner and the software they wrote, they will scan and make public the reader, not as one-to-one digital copy like a downloadable PDF file, but as the output of a series of software experiments.
Chapter 1 - Alice Strete
Techno/Cyber/Xeno-Feminism + carlandre & overunder
output/carlandre.txt: ocr/output.txt
cat $< | python3 src/carlandre.py > $(@)
output/overunder: ocr/output.txt
python3 src/overunder.py

The Intimate and Possibly Subversive Relationship Between Women and Machines Reader explores topics from women's introduction into the technological workforce, the connection between weaving and programming, and using technology in favour of the feminist movement. One major concept that appears throughout the reader is an almost mystical connection between women and software writing, embedded deep in women's tradition of weaving not just threads, but networks. Does software have a gender?

Echoing to her selection of texts, Alice proposes two software based transformation of her reader: carlandre and overunder. carlandre is a program that generates a pattern inspired by the concrete poetry of Carl Andre, it creates a vertical wave of words whose lengths go from ascending to descending and so on. overunder is inspired by the relationship between weaving and programming, this interpreted language written in Python translates simple weaving instructions into a digital interpretation of weaving on text.
Chapter 2 - Joca van der Horst
Who is the Librarian + Reading the Structure
reading_structure: ocr/output.txt
## Analyzes OCR'ed text using a Part of Speech (POS) tagger. Outputs a string of tags (e.g. nouns, verbs, adjectives, and adverbs). Dependencies: python3's nltk, jinja2, weasyprint
mkdir -p output/reading_structure
cp src/reading_structure/jquery.min.js output/reading_structure
cp src/reading_structure/script.js output/reading_structure
cp src/reading_structure/style.css output/reading_structure
cat $< | python3 src/reading_structure/reading_structure.py
weasyprint -s src/reading_structure/print-noun.css output/reading_structure/index.html output/reading_structure/poster_noun.pdf
weasyprint -s src/reading_structure/print-adv.css output/reading_structure/index.html output/reading_structure/poster_adv.pdf
weasyprint -s src/reading_structure/print-dppt.css output/reading_structure/index.html output/reading_structure/poster_dppt.pdf
weasyprint -s src/reading_structure/print-stopword.css output/reading_structure/index.html output/reading_structure/poster_stopword.pdf
weasyprint -s src/reading_structure/print-neutral.css output/reading_structure/index.html output/reading_structure/poster_neutral.pdf
weasyprint -s src/reading_structure/print-entity.css output/reading_structure/index.html output/reading_structure/poster_named_entities.pdf
x-www-browser output/reading_structure/index.html

With Who is the Librarian: The gendered image of the librarian and the information scientist, Joca explores two frequent gender stereotypes: librarianship as a job for women and information science as a male-dominated field. The selection of texts in this reader elaborates on the origin of these stereotypes and the different social status of these professions. This could be the way to answer the question: Who do we want to be the librarian in the future?

Then moving from human interpretation to software interpretation, Joca presents a software, Reading the Structure, that attempts to make visible to human readers how machines, or to be more precise, specific software implementation of text analysis, interpret texts. Computers read a text differently than we do. One of the common methods for software to analyse a text, is to cut the sentences into loose words. Then each word can be labelled for importance, sentiment, or its function in the sentence. During this process of structuring the text, the relation with the original text fades away. Reading the Structure is a reading interface that brings the labels back in the original text. Does that makes us, mere humans, able to read like our machines do?
Chapter 3 - Zalán Szakács
From DIY Book Scanning to the Shadow Librarian + ACCP - Analogue Circular Communication Protocol
Zalán's reader, From DIY Book Scanning to the Shadow Librarian, traces back the beginnings of the shadow libraries starting from the Soviet era of Russia and explores its impact on contemporary academic publishing. Amongst other things, the text selection Informs the reader about activists in this field such as Aaron Swartz, the writer of Guerilla Open Access Manifesto and Alexandra Elbakyan, the founder of Sci-Hub.

Where does the message start? Where does the message end? The user is challenged by the coding tool ACCP to discover the rules behind the circular decoding system and decipher the message. Through the programming language Python and the software DrawBot, words are processed and mapped into a spatial graphical system with the 26 characters of the alphabet and the 10 numbers are arranged around a circle. With a radial stencil placed in front of the graphics, it is possible to turn the images back into words.
Chapter 4 - Natasha Berting
How Bias Spreads from the Canon to the Web + Erase / Replace
erase: tiffs hocrs
python3 src/erase_leastcommon.py
rm $(input-hocr)
rm $(images-tiff)
replace:tiffs hocrs
python3 src/replace_leastcommon.py
rm $(input-hocr)
rm $(images-tiff)

Natasha's contribution explores the politics of selection, transparency and as Johanna Drucker said, "calls attention to the made-ness of knowledge". Her selection of texts explores how human biases and cultural blind spots are transferred from the page to the screen, as companies like Google turn books into databases, bags of words into training sets, and use them in ways that are not always clearly communicated.

The texts will be processed by the Erase / Replace scripts, which are two experiments that question who and what is included or excluded in book scanning. In each script, what is first scanned affects what is visible and what is hidden in what is scanned in a second stage, so on so forth. The scripts learn each page's vocabulary and favours the most common words. The least common word recede further and further away from view, finally disappearing all together or even replaced by the more common words. Every scan session results in a different distortion, and outputs the original scanned image, but with the text manipulated.
Ultimately these texts and scripts are tools for thinking about how knowledge is mined and presented online, how bias spreads from the Canon to the web, finding opportunities to break open this process.
Chapter 5 - Alexander Roidl
Scanning the Database + chatbook
chatbook: ocr/output.txt
python3 src/chatbook.py
oulibot: ocr/output.txt #chatbot based on the knowledge of the scans Dependencies: nltk_rake, irc, nltk
python3 src/oulibot.py

In Scanning the database, Alexander offers to navigate in and out of database narratives. His reader looks at how databases are structured and formed, and how the data they hold are classified, and how such structuring and classification leads to bias. It shows how important it is to question the authoritative dimension of databases, by looking closely at what is being scanned, how it is stored, organized and selected.
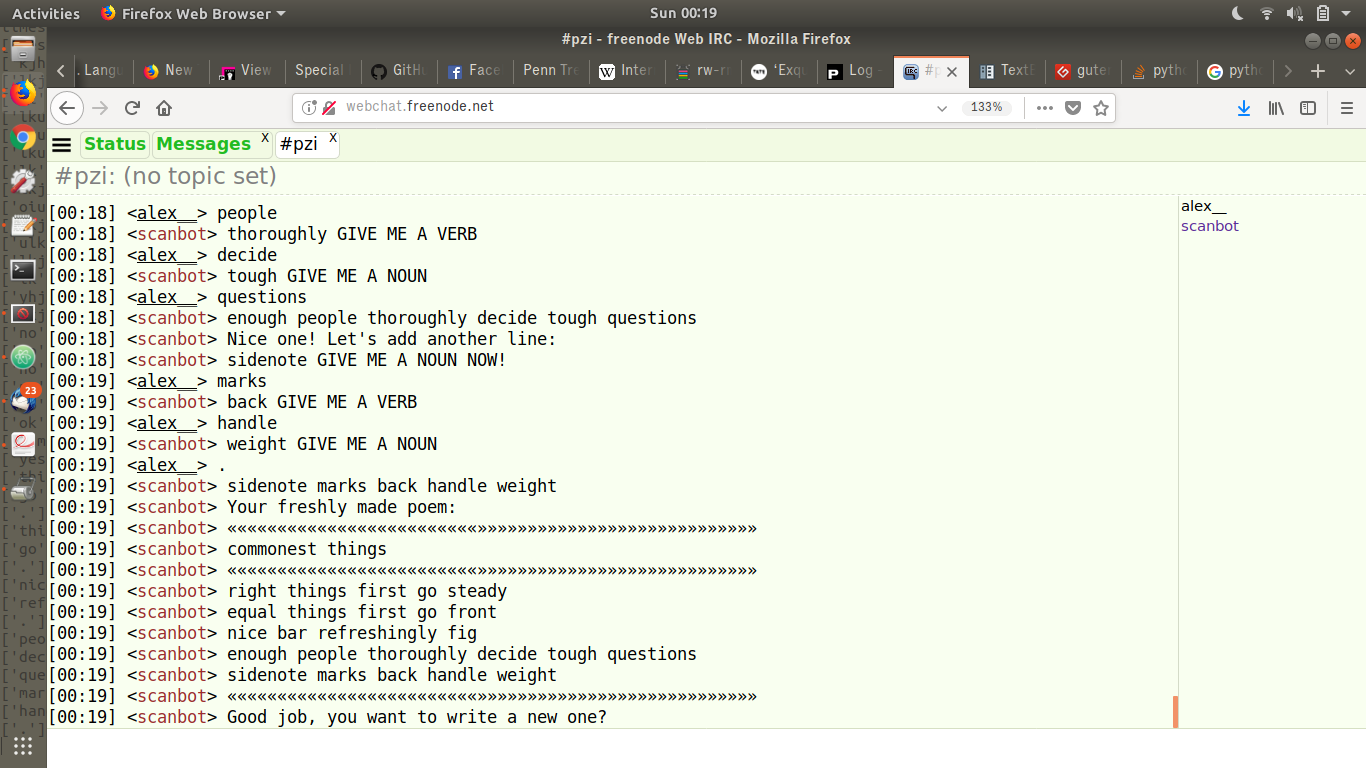
In response to these questions, Alex proposes an alternative interface to such database, by creating a chat bot that enables the user / viewer to explore the content of scanned material by chatting with the books canner. By adding an explicit layer of software mediation, the experiment questions how knowledge is built and mediated in the age of machine learning.
Chapter 6 - Angeliki Diakrousi
From Tedious Tasks to Liberating Orality + ttssr->> Reading and speech recognition in loop
ttssr-human-only: ocr/output.txt
bash src/ttssr-loop-human-only.sh ocr/output.txt

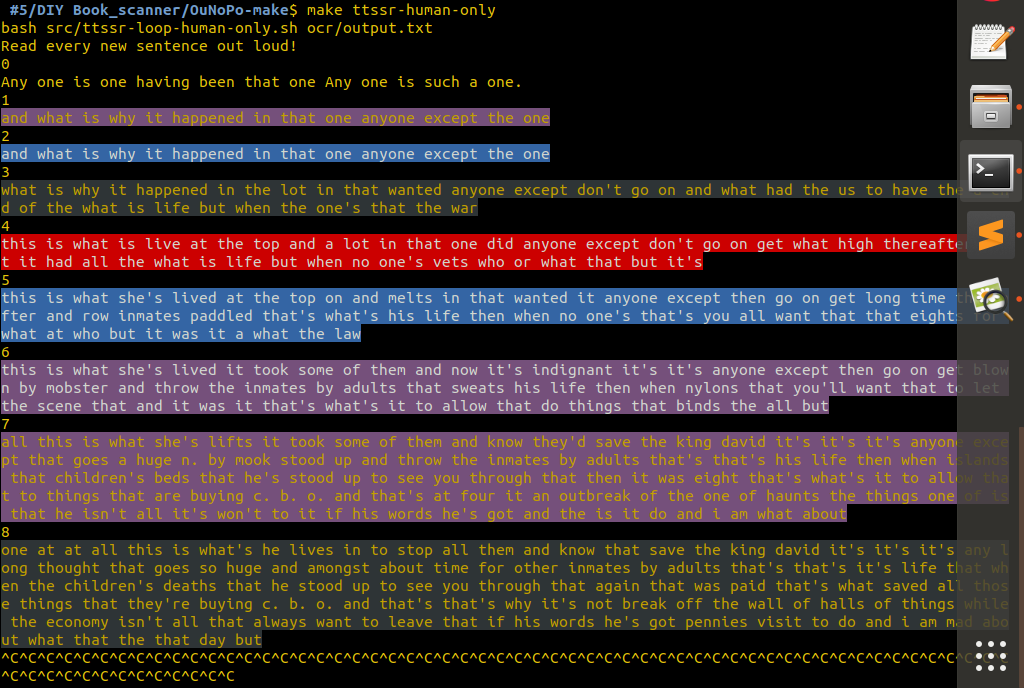
Angeliki's collection of texts From Tedious Tasks to Liberating Orality- Practices of the Excluded on Sharing Knowledge, refers to oral culture in relation to programming, as a way of sharing knowledge including our individually embodied position and voice. The emphasis on the role of personal positioning is often supported by feminist theorists. Similarly, and in contrast to scanning, reading out loud is a way of distributing knowledge in a shared space with other people, and this is the core principle behind the ttssr-> Reading and speech recognition in loop software. Using speech recognition software and python scripts Angeliki proposes to the audience to participate in a system that highlights how each voice bears the personal story of an individual. In this case the involvement of a machine provides another layer of reflection of the reading process.
Credits
OuNuPo was produced as part of a collaboration between XPUB and WORM. The project was developed by the XPUB practitioners (Natasha Berting, Angeliki Diakrousi, Joca van der Horst, Alexander Roidl, Alice Strete and Zalán Szakács) with the support from Varia special guests (Manetta Berends and Cristina Cochior), the WORM Pirate Bay (Wojtek Szustak and Frederic Van de Velde), diybookscanner.eu (Mark Van den Borre) and XPUB staff and tutors (Delphine Bedel, André Castro, Aymeric Mansoux, Michael Murtaugh, Leslie Robbins and Steve Rushton).
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
OuNuPo-Make Code Repository
OuNuPo Make
Software experiments for the OuNuPo bookscanner, part of Special Issue 5
https://git.xpub.nl/OuNuPo-make/
Authors
Natasha Berting, Angeliki Diakrousi, Joca van der Horst, Alexander Roidl, Alice Strete and Zalán Szakács.
Clone Repository
git clone https://git.xpub.nl/repos/OuNuPo-make.git
General depencies
- Python3
- GNU make
- Python3 NLTK
pip3 install nltk
Make commands
Sitting inside a pocket(sphinx): Angeliki
Speech recognition feedback loops using the first sentence of a scanned text as input
run: make ttssr-human-only
Specific Dependencies:
- PocketSphinx package
sudo aptitude install pocketsphinx pocketsphinx-en-us - PocketSphinx Python library:
sudo pip3 install PocketSphinx - Other software packages:
sudo apt-get install gcc automake autoconf libtool bison swig python-dev libpulse-dev - Speech Recognition Python library:
sudo pip3 install SpeechRecognition - TermColor Python library:
sudo pip3 install termcolor - PyAudio Python library:
sudo pip3 install pyaudio
Licenses:
© 2018 WTFPL – Do What the Fuck You Want to Public License. © 2018 BSD 3-Clause – Berkeley Software Distribution
Reading the Structure: Joca
Uses OCR'ed text as an input, labels each word for Part-of-Speech, stopwords and sentiment. Then it generates a reading interface where words with a specific label are hidden. Output can be saved as poster, or exported as json featuring the full data set.
Run: make reading_structure
Specific Dependencies:
- NLTK packages: tokenize.punkt, pos_tag, word_tokenize, sentiment.vader, vader_lexicon (python3; import nltk; nltk.download() and select these models)
- spaCy Python library
- spacy: en_core_web_sm model (python3 -m spacy download en_core_web_sm)
- weasyprint
- jinja2
- font: PT Sans
- font: Ubuntu Mono
License: GNU AGPLv3
Permissions of this license are conditioned on making available complete source code of licensed works and modifications, which include larger works using a licensed work, under the same license. Copyright and license notices must be preserved. Contributors provide an express grant of patent rights. When a modified version is used to provide a service over a network, the complete source code of the modified version must be made available. See src/reading_structure/license.txt for the full license.
Erase / Replace: Natasha
Receives your scanned pages in order, then analyzes each image and its vocabulary. Finds and crops the least common words, and either erases them, or replaces them with the most common words. Outputs a PDF of increasingly distorted scan images.
For erase script run: make erase
For replace script run: make replace
Specific Dependencies:
- NLTK English Corpus:
- run NLTK downloader
python -m nltk.downloader - select menu "Corpora"
- select "stopwords"
- "Download"
- run NLTK downloader
- Python Image Library (PIL):
pip3 install Pillow - PDF generation for Python (FPDF):
pip3 install fpdf - HTML5lib Python Library:
pip3 install html5lib
Notes & Bugs:
This script is very picky about the input images it can work with. For best results, please use high resolution images in RGB colorspace. Errors can occur when image modes do not match or tesseract cannot successfully make HOCR files.
carlandre & over/under: Alice Strete
Person who aspires to call herself a software artist sometime next year.
License:
Copyright © 2018 Alice Strete This work is free. You can redistribute it and/or modify it under the terms of the Do What The Fuck You Want To Public License, Version 2, as published by Sam Hocevar. See http://www.wtfpl.net/ for more details.
Dependencies:
Programs:
carlandre
Description: Generates concrete poetry from a text file. If you're connected to a printer located in /dev/usb/lp0 you can print the poem.
run: make carlandre
over/under
Description: Interpreted programming language written in Python3 which translates basic weaving instructions into code and applies them to text.
run: make overunder
Instructions:
- over/under works with specific commands which execute specific instructions.
- When running, an interpreter will open:
> - To load your text, type 'load'. This is necessary before any other instructions. Every time you load the text, the previous instructions will be discarded.
- To see the line you are currently on, type 'show'.
- To start your pattern, type 'over' or 'under', each followed by an integer, separated by a comma. e.g. over 5, under 5, over 6, under 10
- To move on to the next line of text, press enter twice.
- To see your pattern, type 'pattern'.
- To save your pattern in a text file, type 'save'.
- To leave the program, type 'quit'.
oulibot: Alex
Description: Chatbot that will help you to write a poem based on the text you inserted by giving you constraints.
run: make oulibot
Dependencies:
Python libraries:
- irc :
pip3 install irc - rake_nltk Python library:
pip3 install rake_nltk - textblob:
pip3 install textblob - PIL:
pip3 install Pillow - numpy:
pip3 install numpy - tweepy:
pip3 install tweepy - NLTK stopwords:
- run NLTK downloader
python -m nltk.downloader - select menu "Corpora"
- select "stopwords"
- "Download"
- run NLTK downloader